
GCN and Keplar
Now i will conclude my article with a short overview on two main GPU architecture used these days : GCN and Keplar
GCN Architecture(AMD):
The building block of a GCN architecture is Compute Engine. So we will just discuss the basic design of a compute Engine.
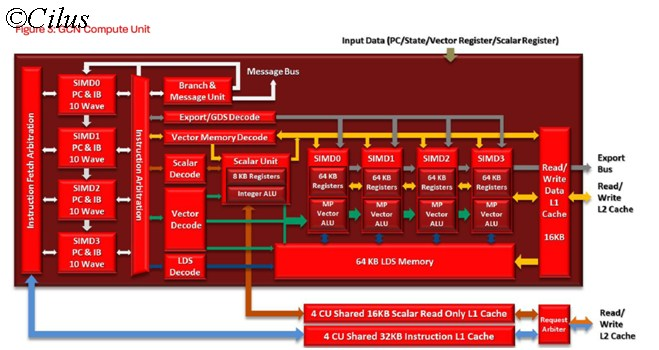
A Compute Engine or Compute Unit of GCN is comprised of 4 SIMD units, each with their own execution units and 64KB Register cache, one Scalar unit (with 8KB register cache and Scalar unit), separate Vector and Scalar Decode engine, a dedicated Branch prediction unit which predicts the conditional jumps (example: if i>0 then C = A + B Else C= A-D; A,B,C,D being Vectors). Also a 64 KB LDS memory is shared by all the four SIMD unit. A Read-Write unit is present which performs the read from memory and write back to memory operations. Each of the SIMD unit has 16 Vector execution unit, totaling 64 Vector Execution unit per CU. In other words, a single CU can perform a single operation over 64 data simultaneously. Now if you compare this design with the block diagram of the Vector Processor, you will find lots of similarities; in fact a single CU looks like a complete vector Processor which can perform a single operation over 64 data items simultaneously. This is the main advantage of GCN design as each of the CU can perform its operations independently without the help from other components as everything is placed inside a single CU.
As a result, if the CU count is increased, both the Graphics processing performance as well as the Compute performance will be increased proportionally.
Also, in the block diagram, you are seeing a new term called Wave or Wavefronts, which without going into details, can be considered a Thread for GPU. A wavefront can have maximum of 64 data items but they can come from a single operation (one operation to be performed over 64 data items) or from multiple operations ( 4 different operations to be performed, each over 16 data items, totaling 64 data-items).
As shown in the picture, 10 Wavefronts, each with 64 Data items, are available for each of the SIMD units, resulting a total 40 Wavefront assignment or (40X64)=2560 work-item assignment for just a single CU. Then each of the SIMD unit will pick one Wavefront from the 10 Wavefront assigned to them, resulting simultaneous execution of 4 Wavefronts.
Now here comes the best part:-
Suppose SIMD 0 has 10 Wavefronts, W1 to W10, assigned to it. Now while executing W2, it is observed that W2 is dependent upon another wavefront W4, SIMD0 will just save the current state of W2 in the Register cache associated to it and then pick up W4 for execution. Once W4 is finished and the results are available, it will fetch W2 from the registers and start executing it from the point where it was stalled. This is very similar to the Out of Order execution of a CPU and a feature not present in previous VLIW design.
Kepler Architecture(Nvidia)
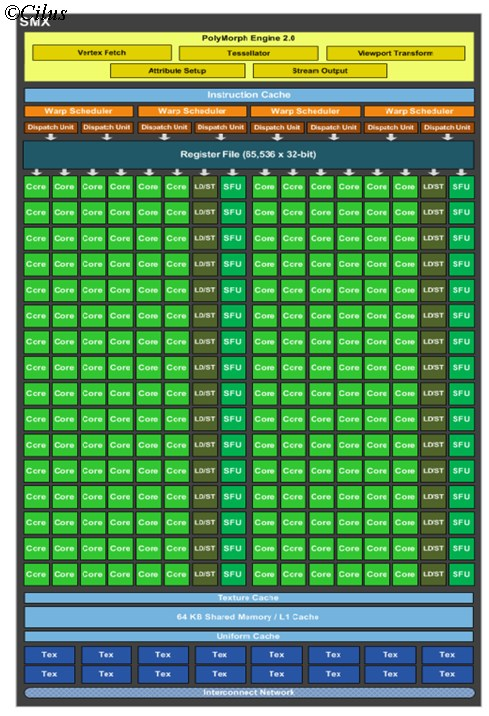
The building block of Kepler architecture is SMX or Streaming Multiprocessor. Each of the SMX unit is comprises of mainly 192 CUDA cores or Stream processors, 32 SFU or Special Functional Units, 4 Wrap Schedulers and 32 Load-Store units. Each of the 192 Stream Processor can perform operation over a single Data item, resulting maximum capability of performing a single operation over 192 data items. SFU can perform some special operations over the data.
Now one technical thing, just like Wavefront in case of AMD, Wrap is the term used by Nvidia to explain a thread. The Wrap schedulers schedules the threads to the available 192 stream processors and we have four of them to schedule a single SMX. So at a time, 4 Wraps or thread can be scheduled by a SMX unit, and each will be assigned to be executed by a cluster of (192/4) = 48 Stream Processors.
Now there are two problems with this approach, when compared to GCN :
1st: If the count of stream processors are increased inside a SMX, say from 192 to 216, although the Graphics processing performance will increase almost proportionately, the compute performance will not. Because here the number of schedulers remain same for the SMX, only 4 and now they have to manage 216 stream processors. So Wrap Scheduler’s performance also need to be increased.
2nd: Nvidia was facing problems from their Fermi design to integrate a scheduler which is optimized for both Graphics and compute performance. In GTX 480, that has been done which leaded to higher transistor counts and huge power consumption.
In Kepler, Nvidia didn’t optimize their Scheduler for compute performance. Instead they just have provided minimum features which can handle current generation texture, Pixel and Vertex operations of Games properly. It reduced the production cost, power consumption and heating issues but in a cost of terribly weak compute performance.
So there you have it..a few words on the GPU
Signing off
Suryashis aka Cilus
Have questions,comment etc? Discuss it here :
{kind=link}